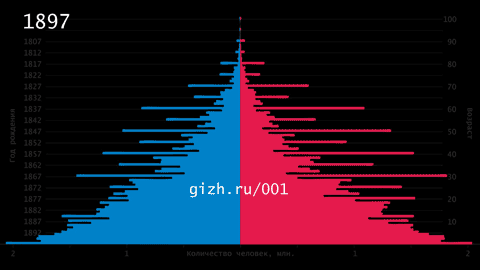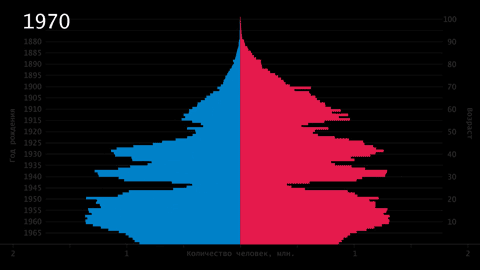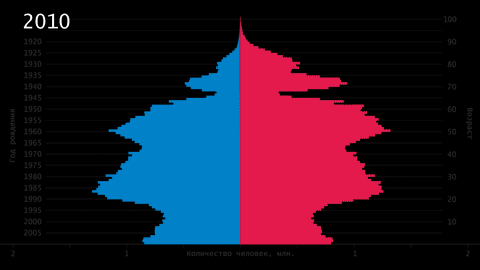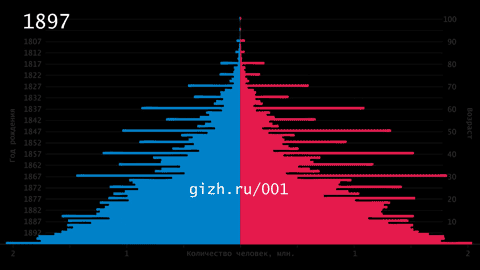
Карта России с регионами, пропорциональными населению
Что это?
Для изображения социально-экономической статистики России я использую карту с площадью регионов, пропорциональной населению. Новые карты я публикую ВКонтакте и в Фейсбуке под хэштегом #картапролюдей. Вот любимые (2018-01-05):
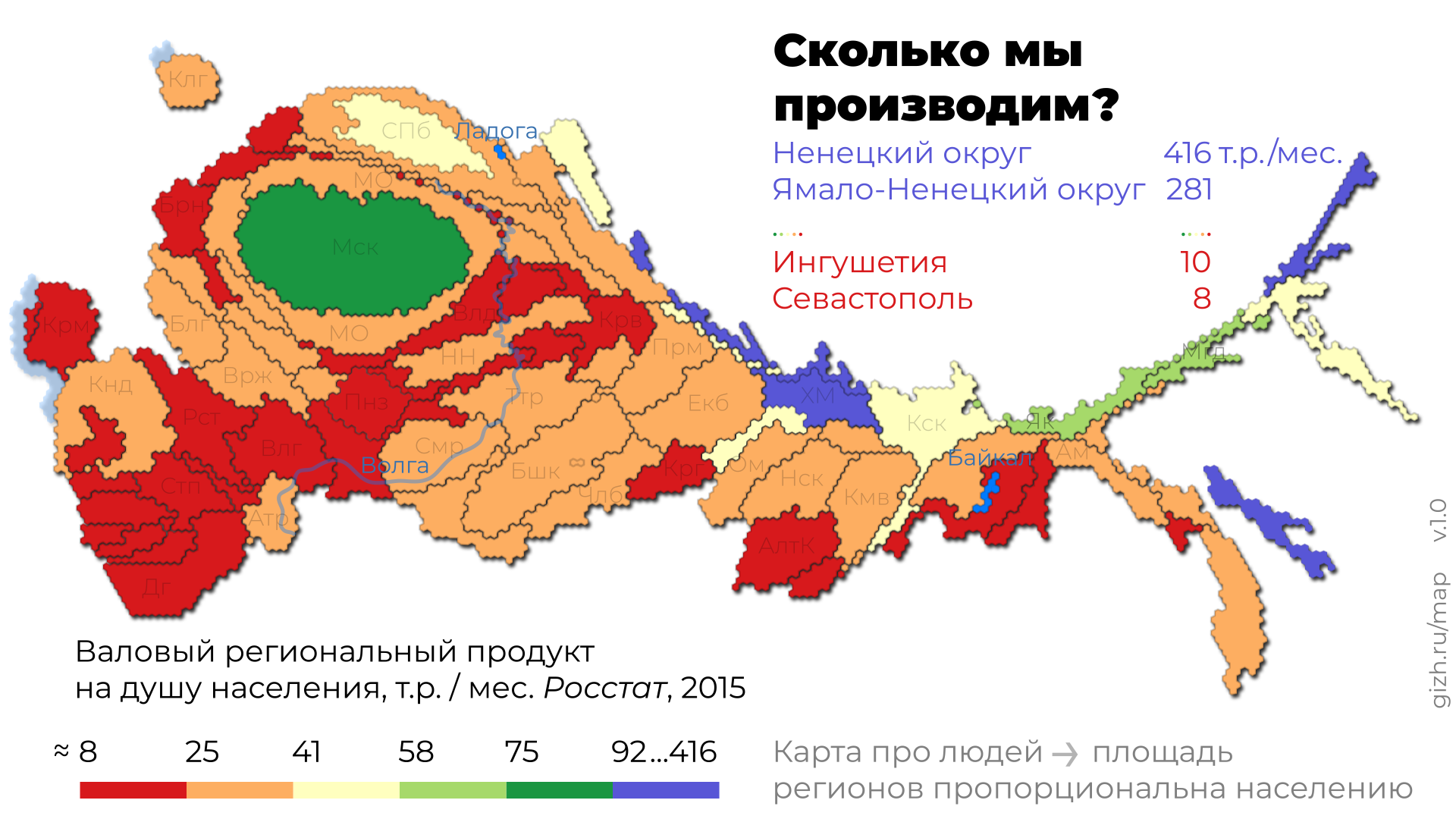
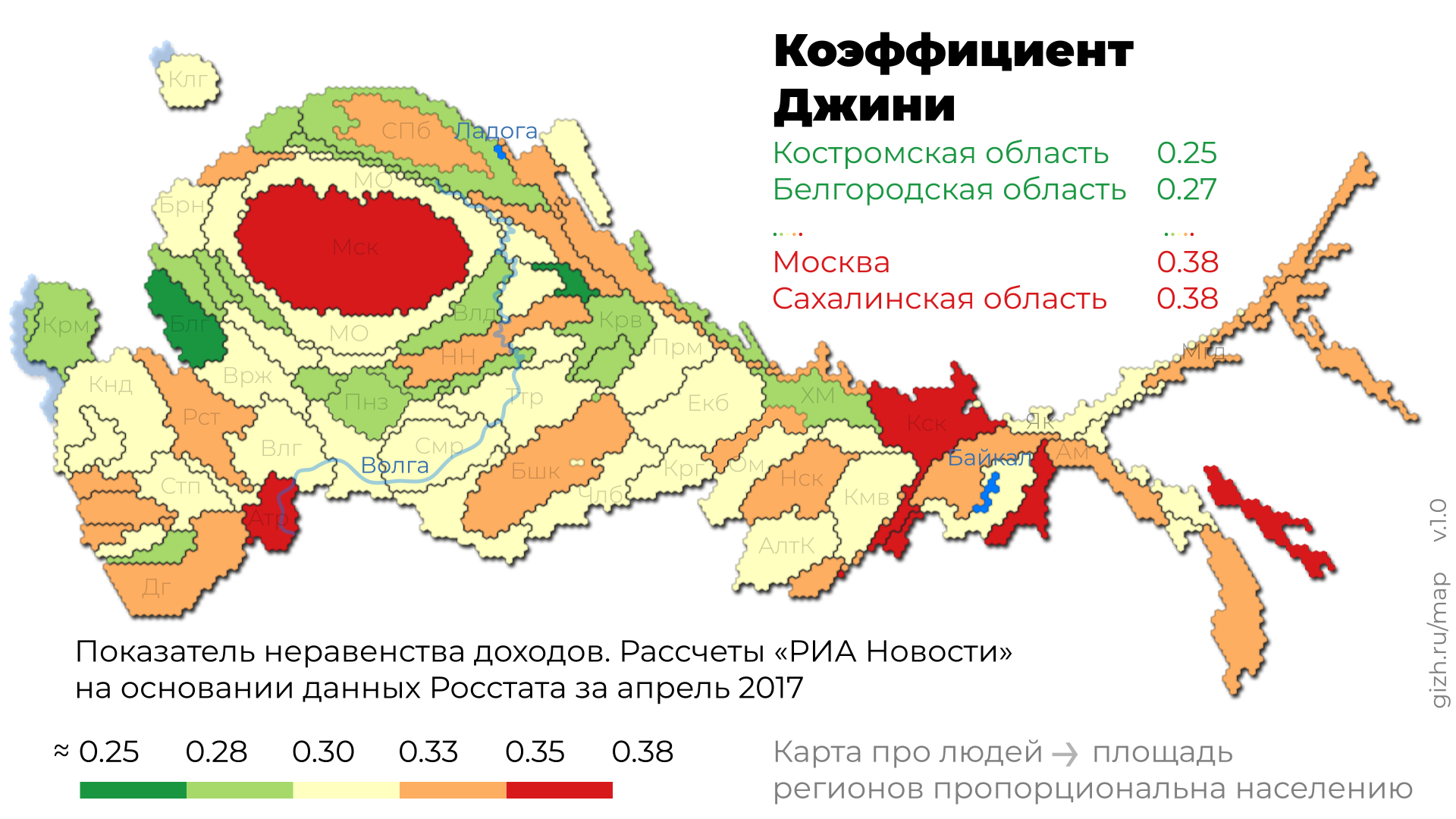
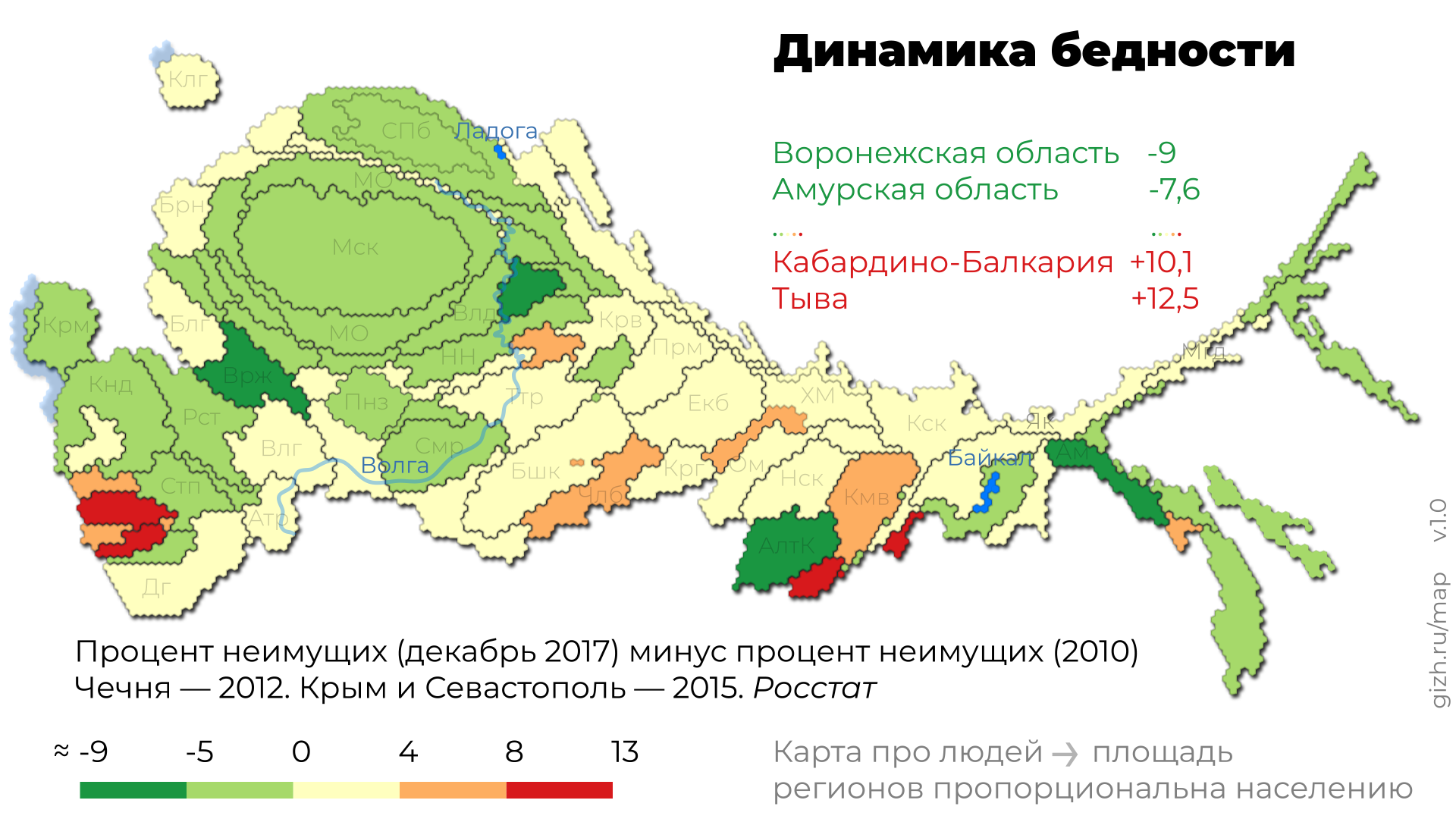
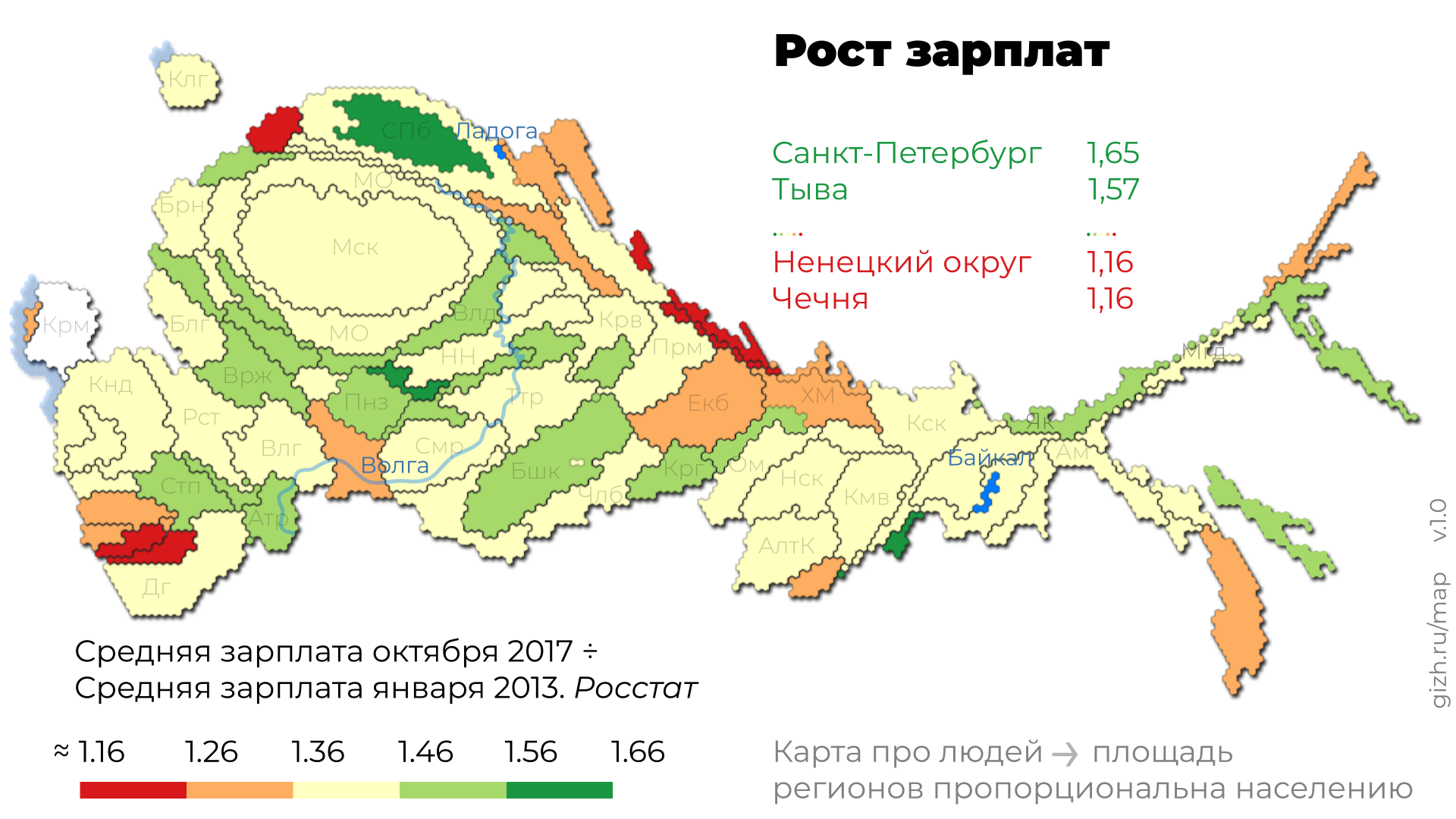
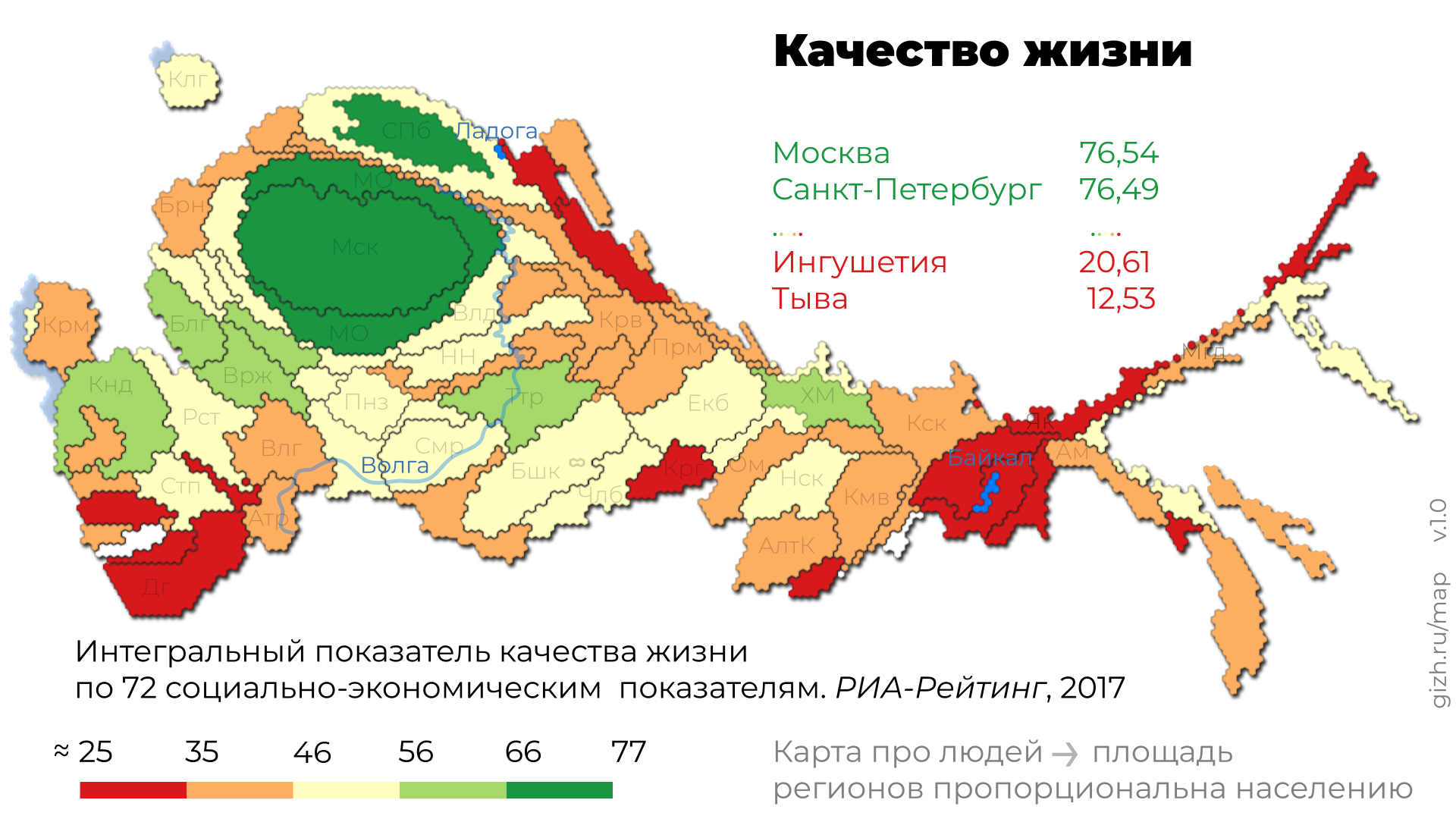
Это приспособленная для повседневного использования анаморфоза Дмитрия Скугаревского. По ссылке — интерактивная версия и описание картографического алгоритма.
Почему?
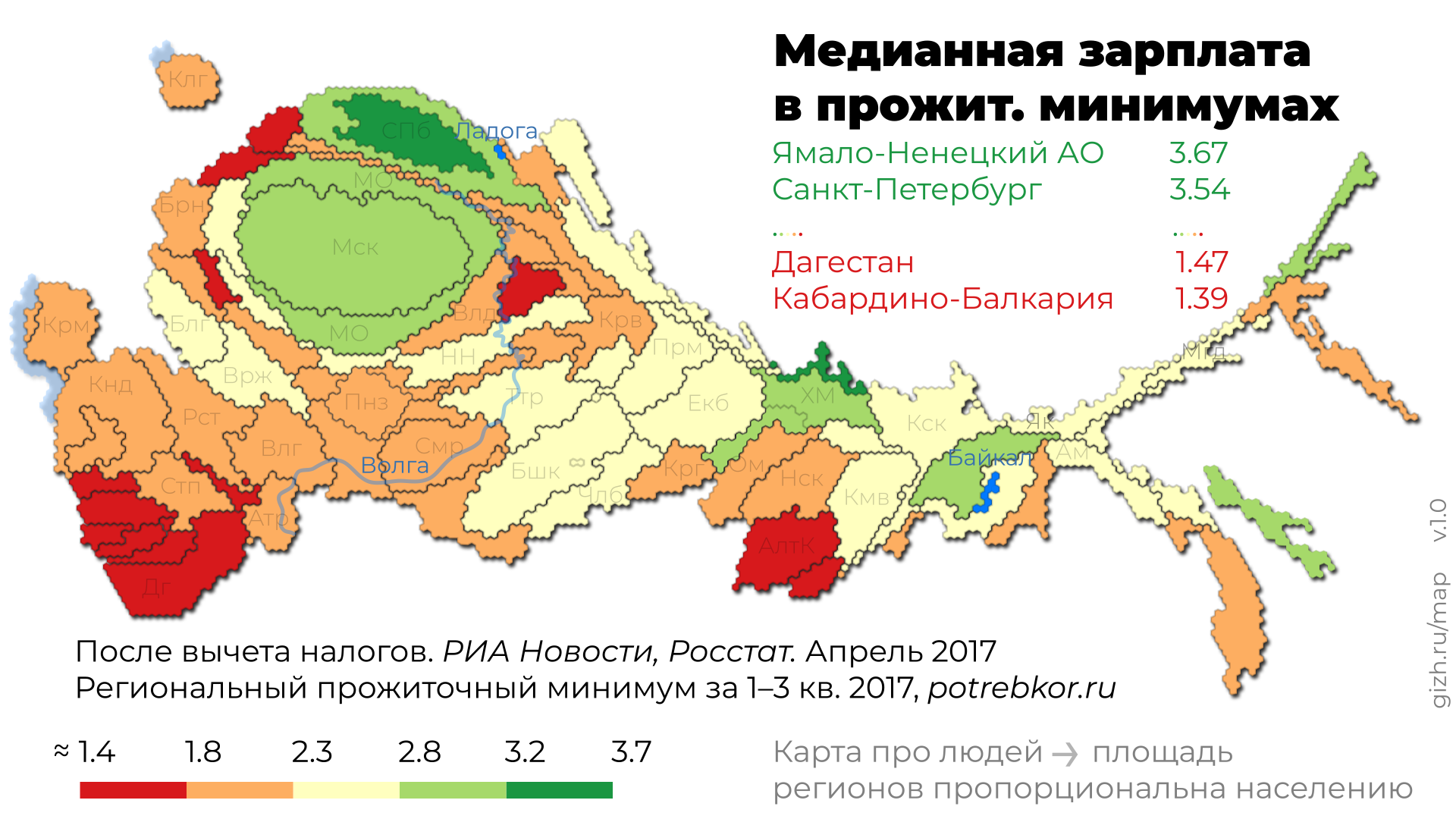
Россия в силу своей своеобразной географии плохо получается на обычных картах. Плохо — значит, что картинка не адекватна реальности. Сравним две карты на одном наборе данных.
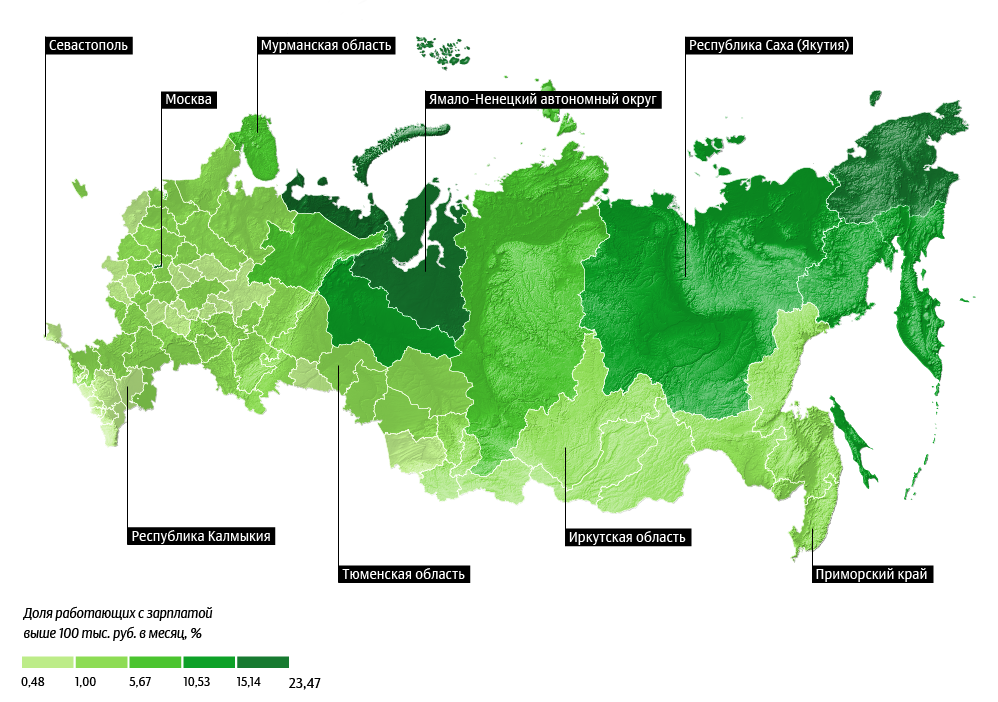
Это фрагмент карты «РИА Новости».
Это карта, анаморфированная по населению.
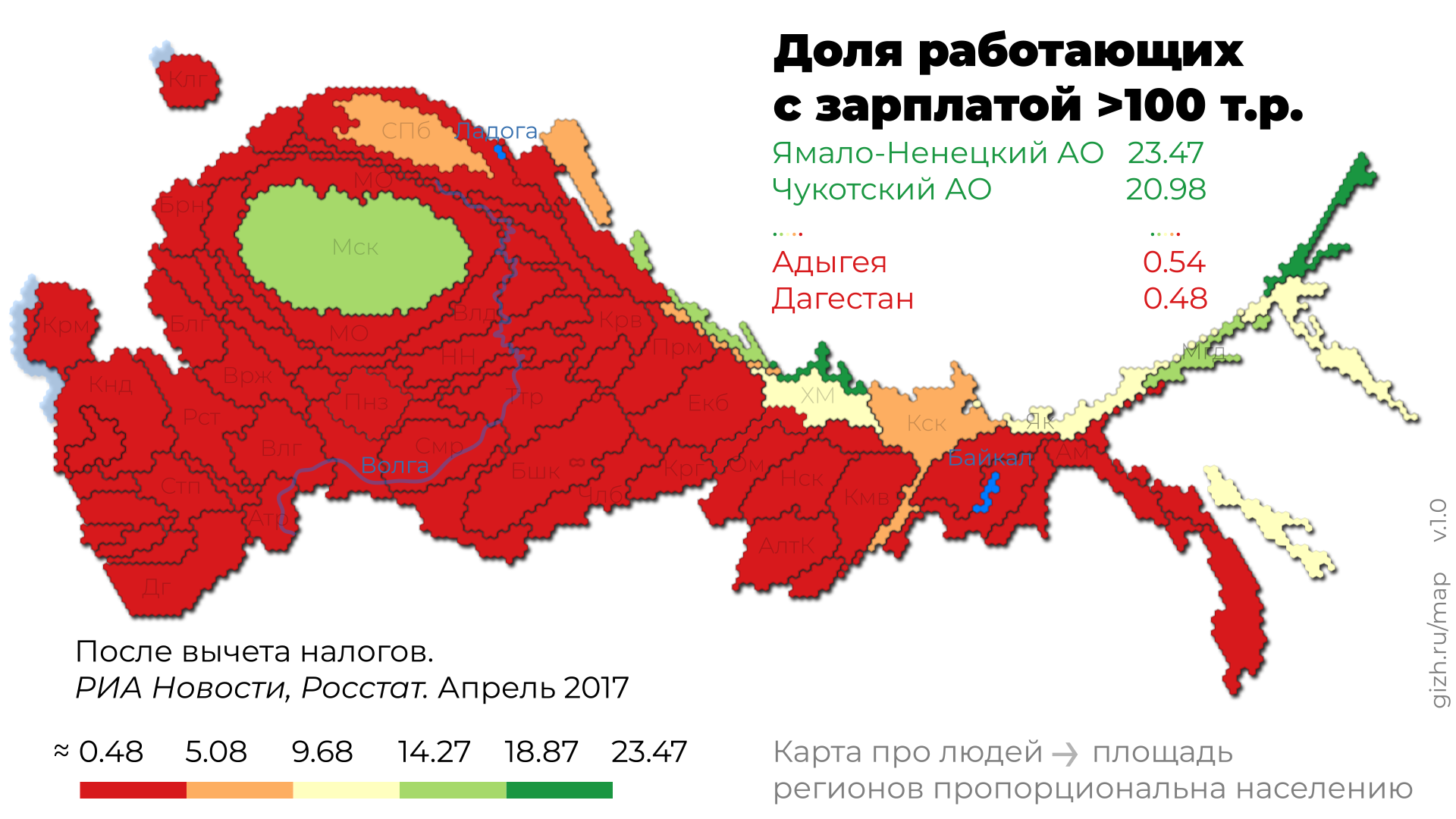
Первая карта говорит: на Севере — зарабатывают. Вторая карта говорит: ага, пара человек.
Зарплаты зарабатывают люди, а не гектары. И мы делаем карту про людей, а не про административно-территориальные границы.
Классическая карта подходит для социально-экономической статистики в одном случае: если вы имеете дело с регионами как статистическими единицами. Допустим, вы чиновник, которому нужно, чтобы не больше, чем в 10 регионах смертность была больше 20 у.е., а сколько там людей живет — дело другого департамента.
Планы и сотрудничество
- Я считаю, что карта, анаморфированная по населению, даёт верное представление о России, и что большая ошибка, что её не используют начиная со школьных атласов, и что это необходимо исправить.
- Когда одно из крупных медиа начнет использовать анаморфированную по населению карту — тогда я буду считать проект законченным.
- Следует сделать очень много карт. Если есть наборы данных — присылайте.
- Следует перерисовать карту, сейчас она довольно небрежная.
- Следует улучшить макет карты: подписи, географические объекты, верстка.
- Следует сделать интерфейс, с помощью которого любой пользователь мог бы создать карту на основе своего набора данных.
- Однажды кто-нибудь сделает аналогичный глобальный проект, возможно, на основе таких или таких карт.
История версий
Версия 1.2
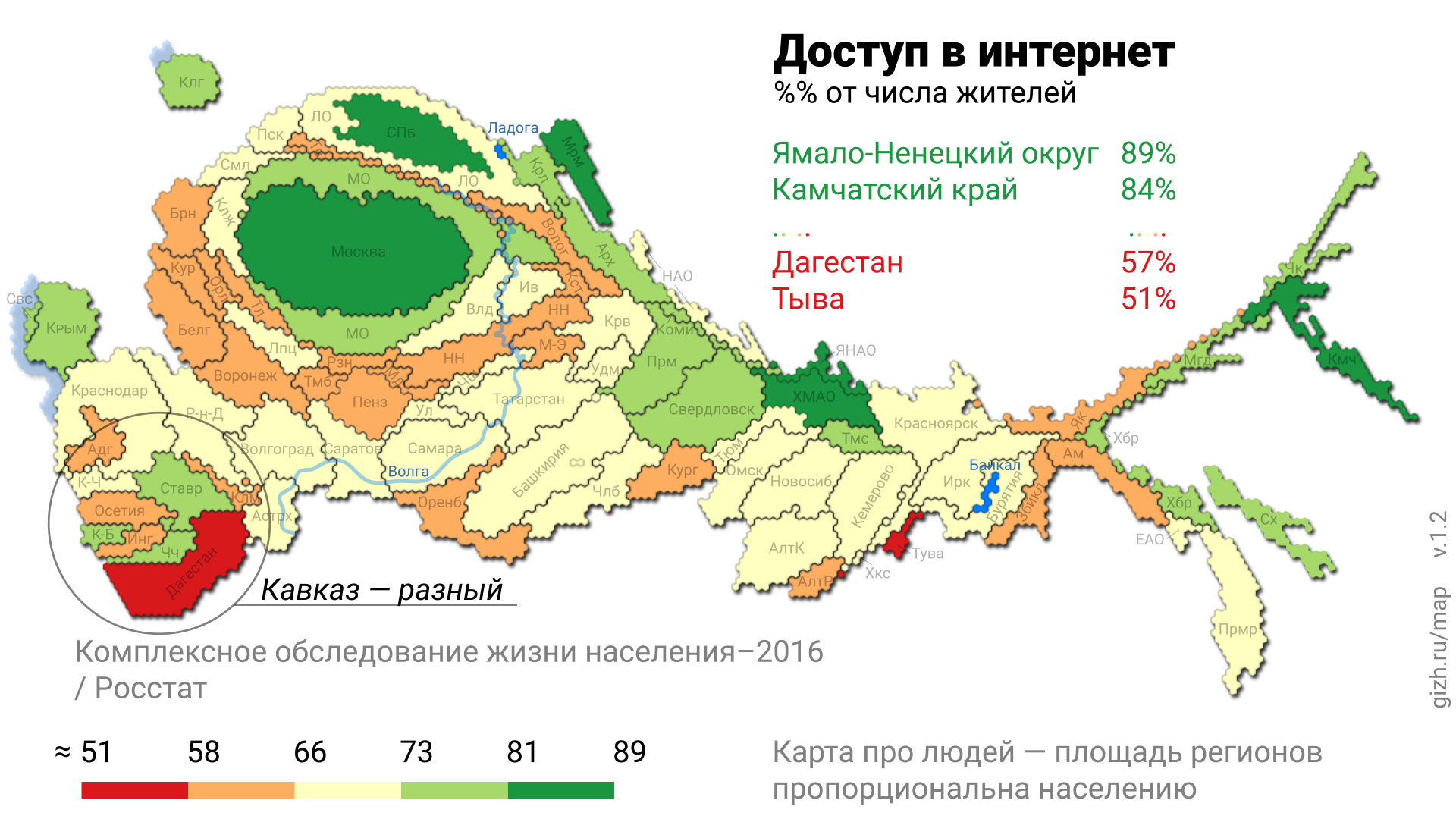
- Шрифт поменял на более узкий и более читаемый.
- Подписал все регионы
- В этот момент проект свернул в интерактивные, но не анаморфированные, карты. Потом от него отпочковалась еще плиточная карта — ну, к анаморфам вернемся попозже.
Версия 1.0.
- Отрисована и настроена для быстрого креатива карта Дмитрия Скугаревского.
- Цветовую схему взял у ColorBrewer. Отказался от градиента, чтобы нейтральным цветом отображалось более-менее медианное значение, светофорными красным и зелёным — отклонения.
- Цвета распределены по принципу equal intervals area. В общем случае — пять интервалов. В случае больших выбросов отдельных регионов добавляется шестой (синий), объединяющий экстремальные значения.
- Ладожское озеро перенес на границу между ЛО и Карелией.
- Добавил границы автономных округов (НАО, ХМАО, ЯНАО).
- Добавил избранные моря.